前回の続き
今回は、変数の扱いについて説明していきます。
変数宣言
これまで、変数というのは使わずにきましたが、SQLでも変数を使う場面というのは多分にあります。
例えば、システムに組み込むときに、WHERE句の抽出条件を可変にしたいときに、引数から代入したいときなど変数を使うことになろうと思います。
では、早速使い方の説明です。
まずは、変数の作り方です。
変数を作ることを、変数を宣言するといいます。
以下の通り変数宣言できます。
DECLARE @変数名 データ型
※変数名の頭には必ず@をつけてください。
具体的にやってみます。
数値型の変数と、10文字までの文字型変数を作ります。
※データ型についてもっと調べたい方は、ここあたりがよいかとおもいます。
DECLARE @NUM INT
DECLARE @TXT NVARCHAR(10)
こんなかんじで変数宣言ができます。
変数に値を代入する。
変数が出来たら値を入れないと意味がありません。
変数に値を入れる方法はこんな感じです。
SET @変数名 = 値
具体的に値を入れてみるとこんな感じです。
SET @NUM = 123 SET @TXT = 'あいうえお'
変数宣言と代入をセットで行うこともできる。
表題のままだが、そんなこともできる。
DECLARE @変数名 データ型 = 値
具体的にはこんな感じ
DECLARE @NUM INT = 123 DECLARE @TXT NVARCHAR(10) = 'あいうえお'
変数を使ってみる
変数はさまざまなところに応用できます。
個々ではいくつかの例を試してみたいと思います。
Person.Person テーブルからBusinessEntityIDをWHERE句で抽出する際に、値を変数からもってくるようにします。
DECLARE @NUM INT = 123 SELECT * FROM Person.Person WHERE BusinessEntityID = @NUM
結果は以下の通り

変数の値を変えることで、抽出結果を変えられるのでこれから先の応用では必要な手法になってきます。
IF文に使ってみる
DECLARE @NUM INT = 123 DECLARE @TXT NVARCHAR(10) = 'あいうえお' IF @NUM = 123 PRINT @NUM ELSE PRINT @TXT
結果はこんな感じ
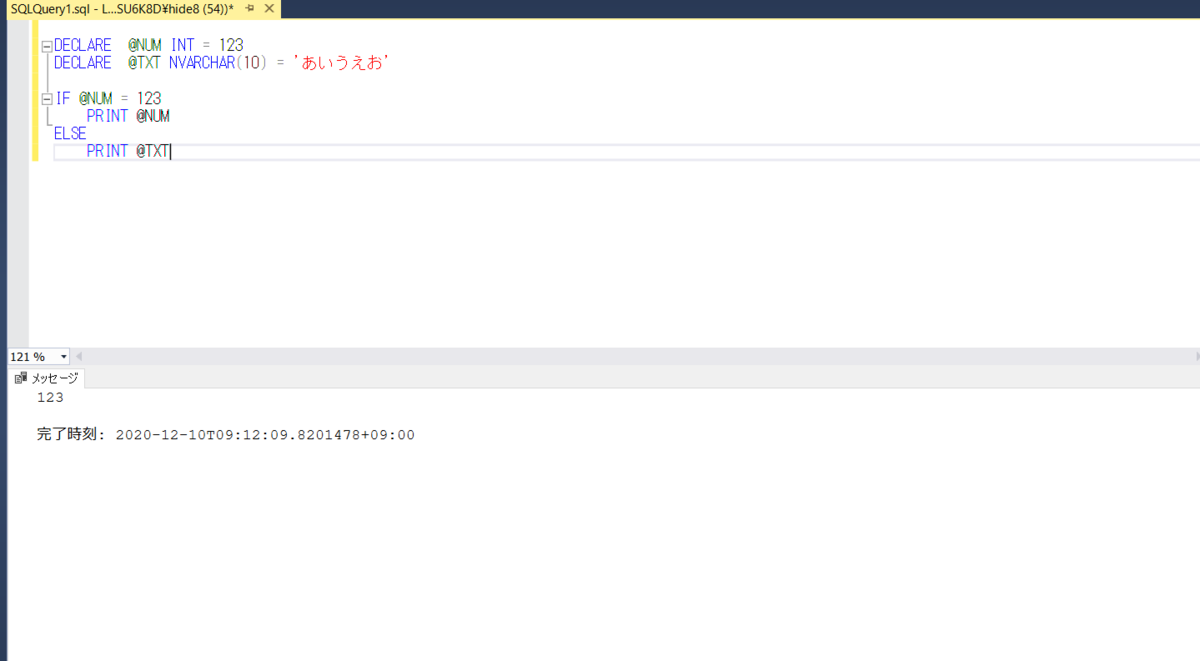
結果からわかるように、作成した変数はスカラなので、活用場所がスカラであればほぼどこでも使えます。
以上、今回はここまで。